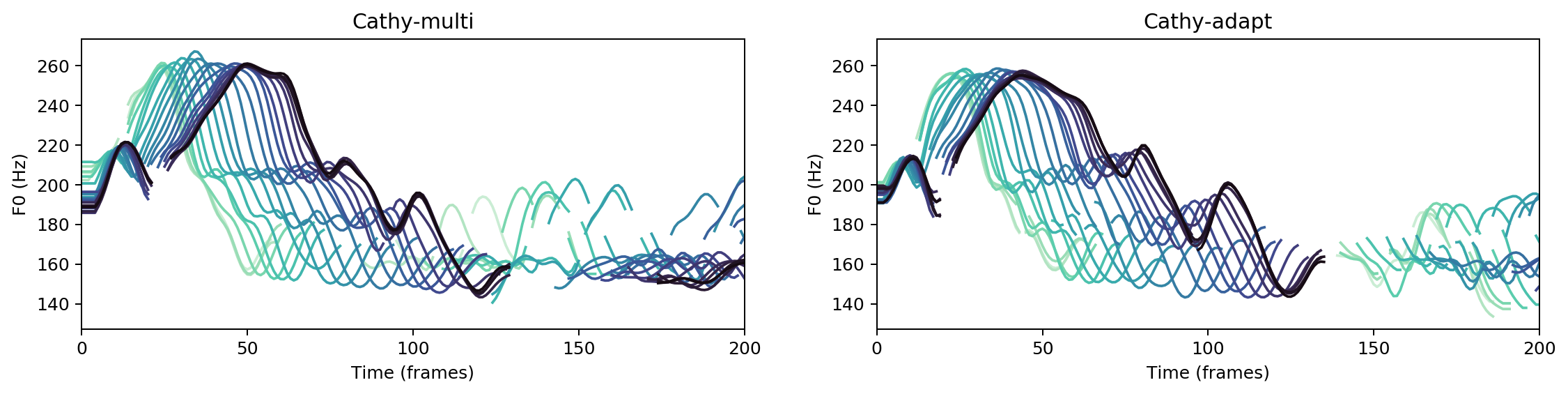
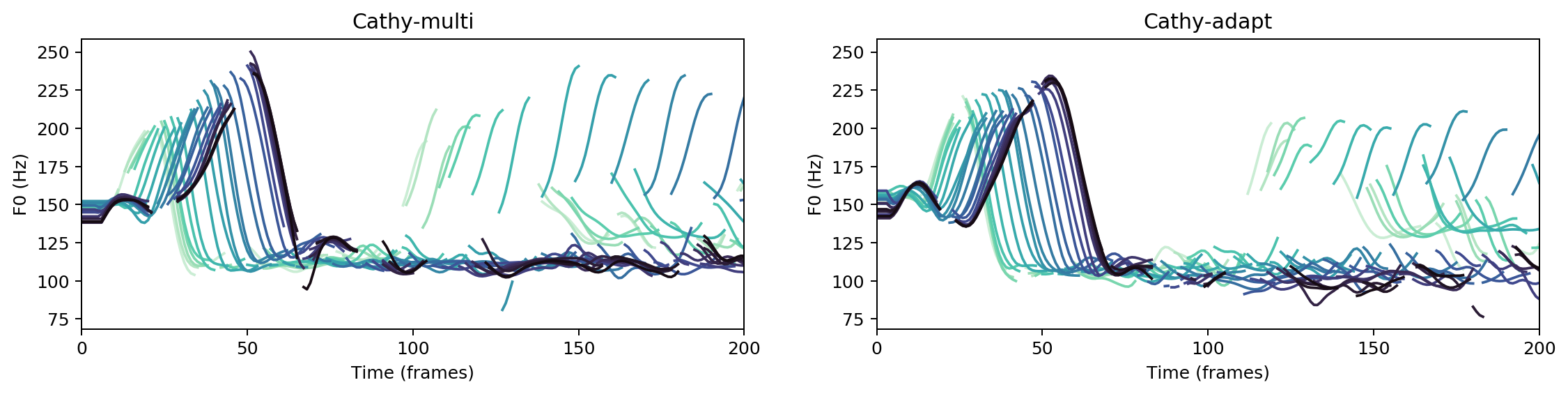
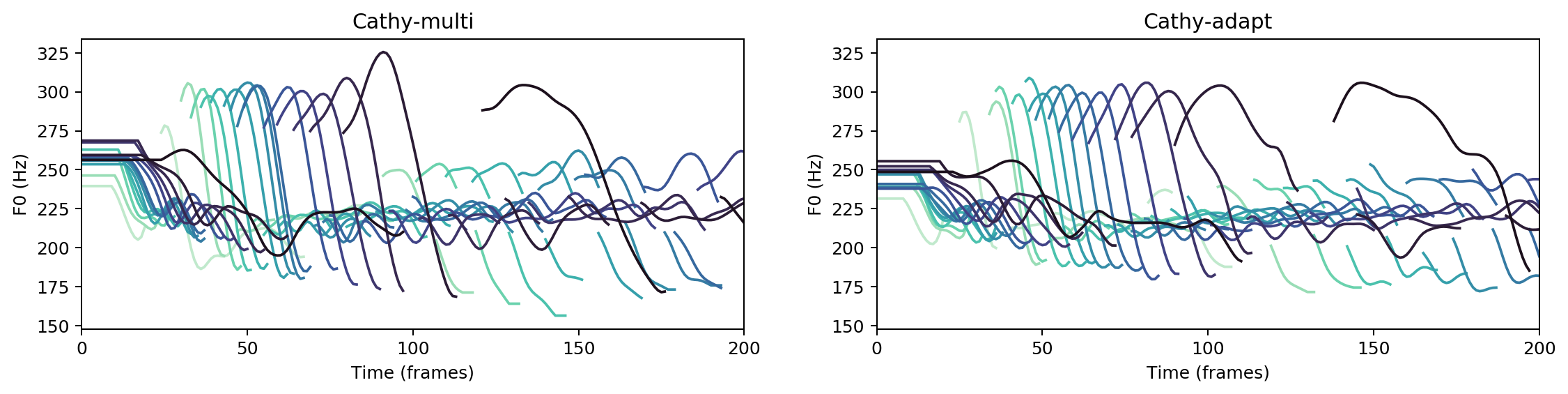
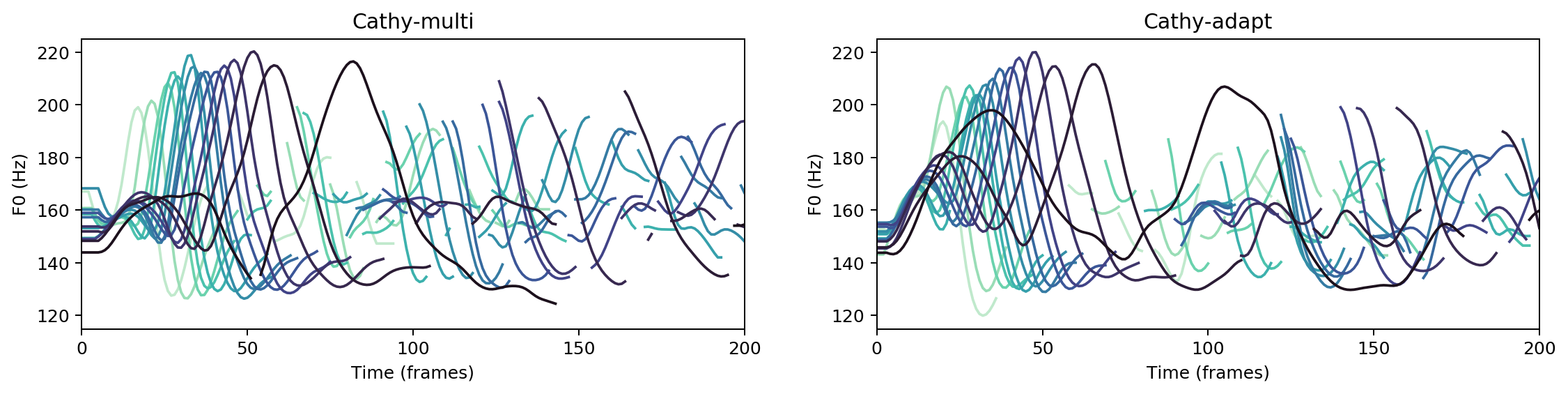
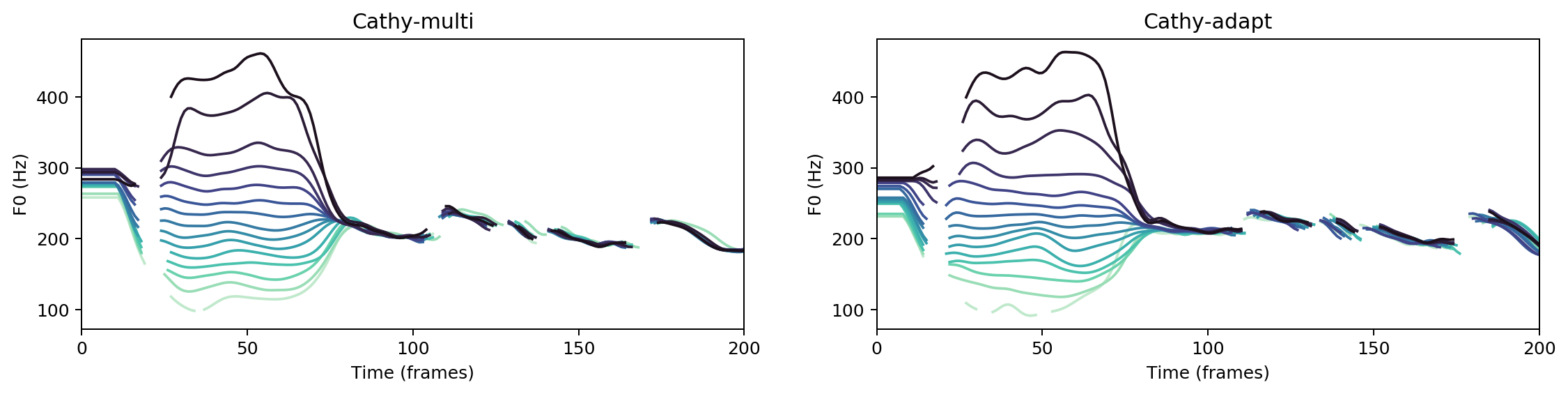
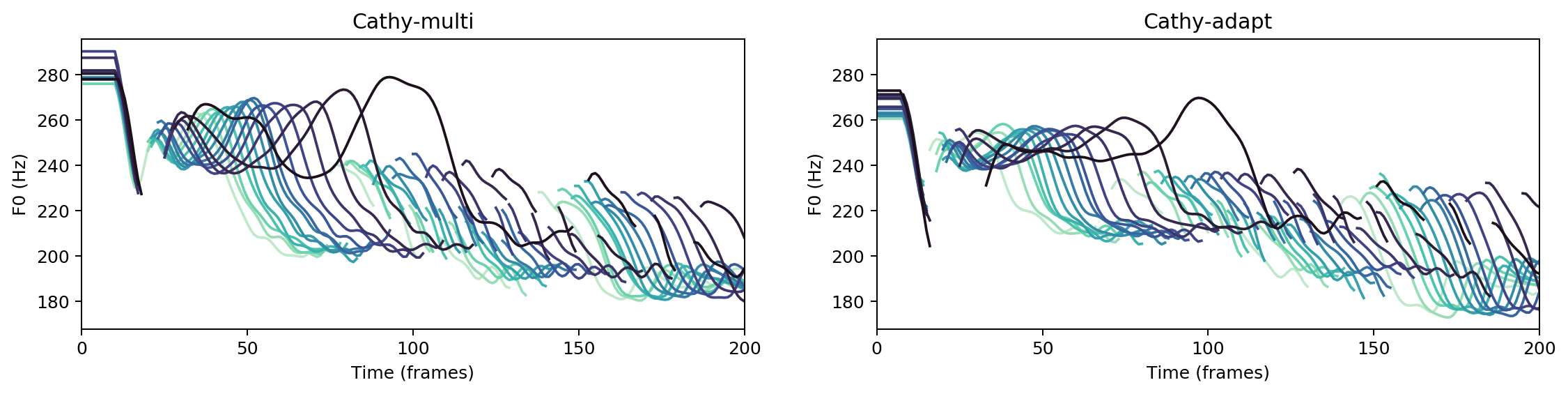
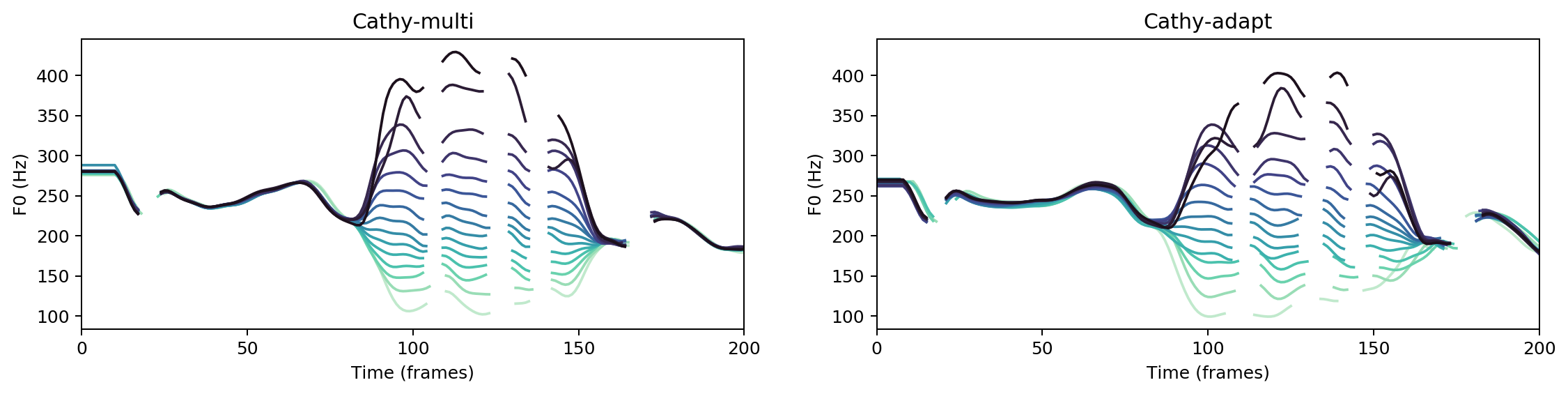
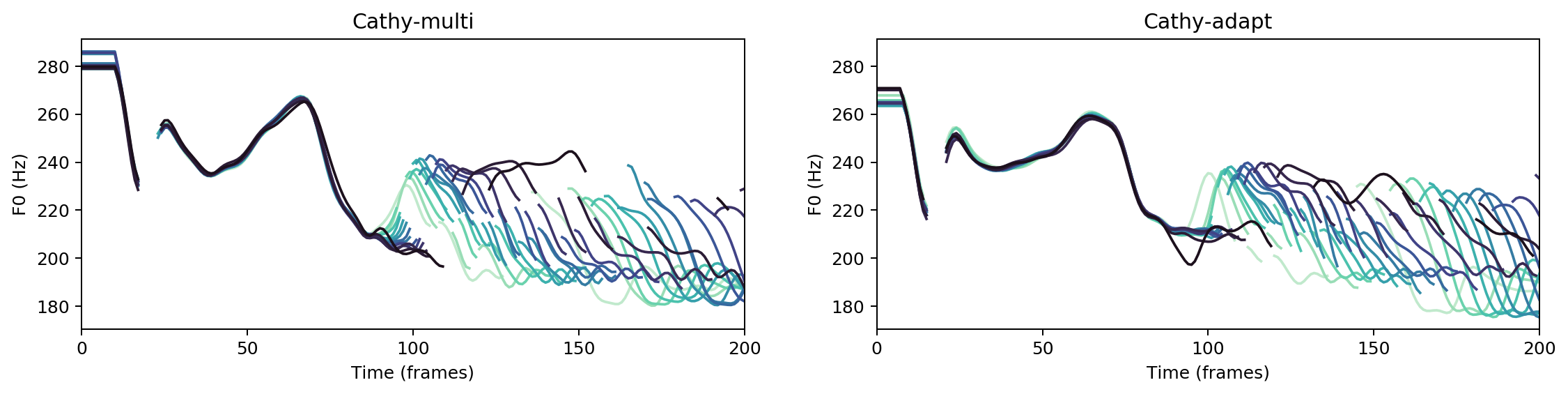
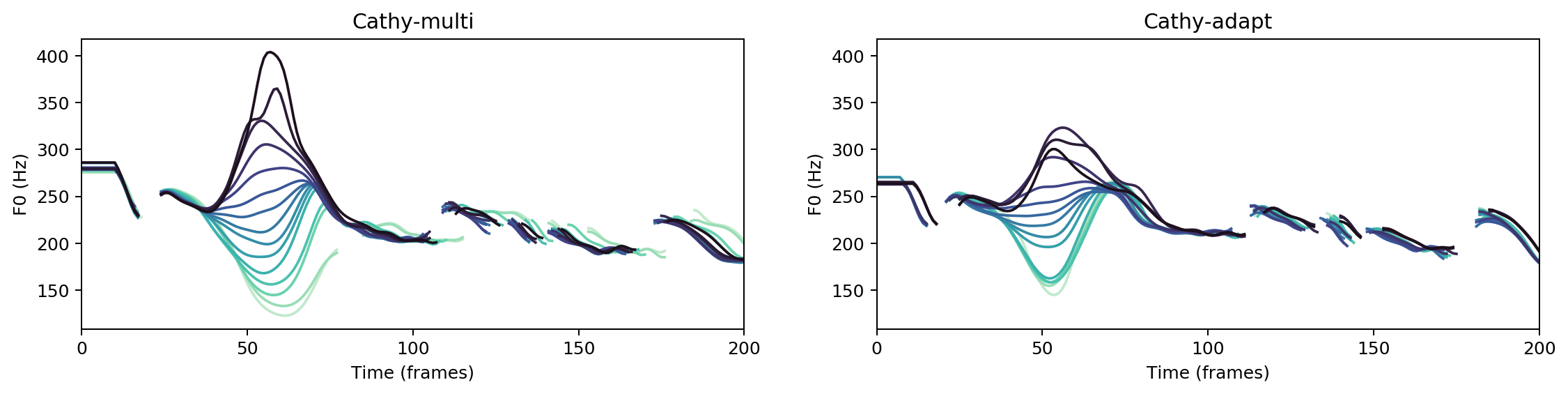
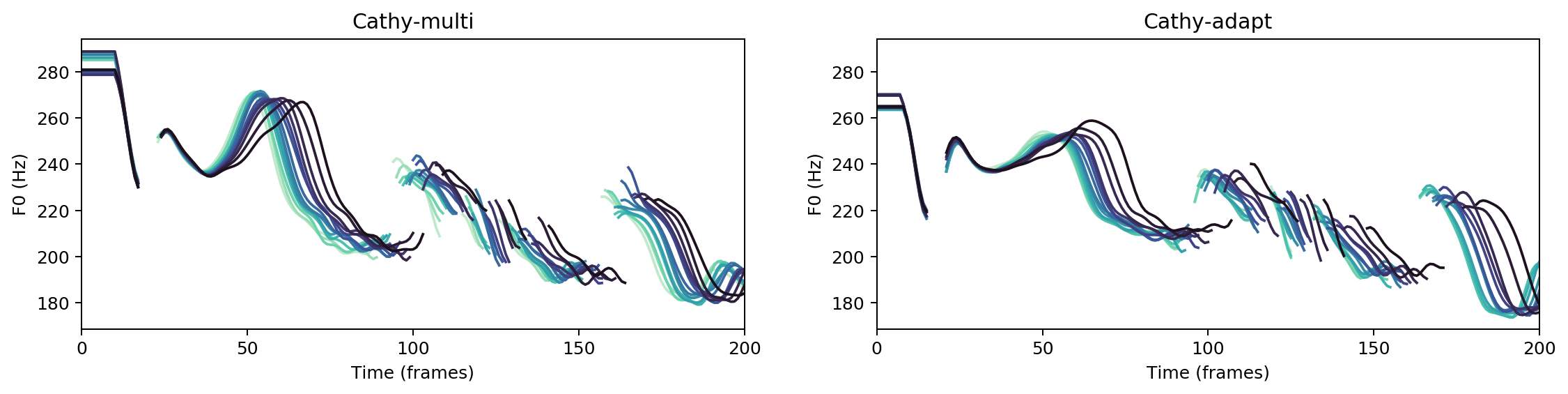
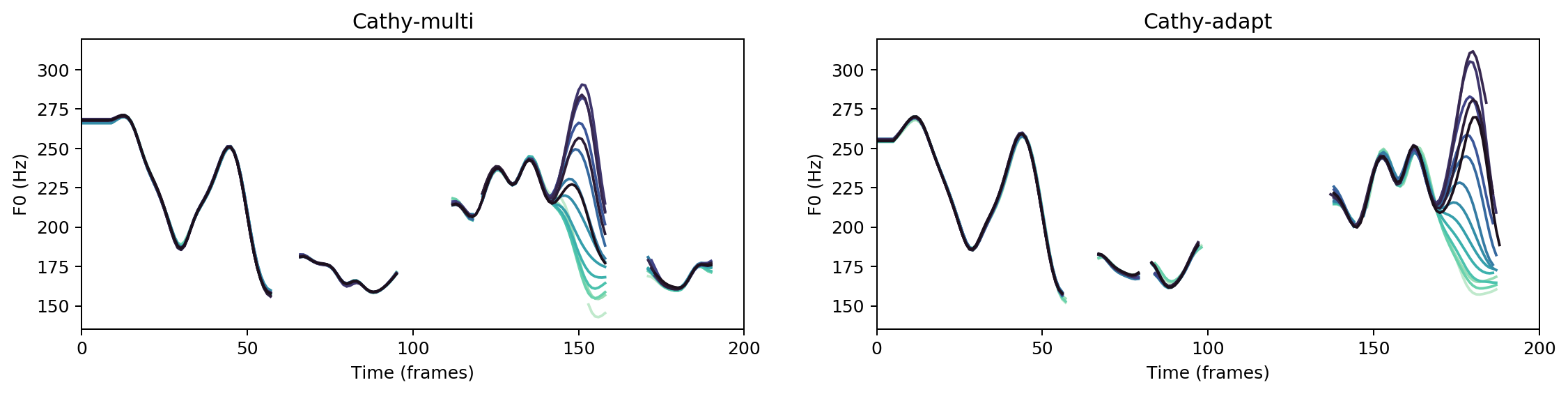
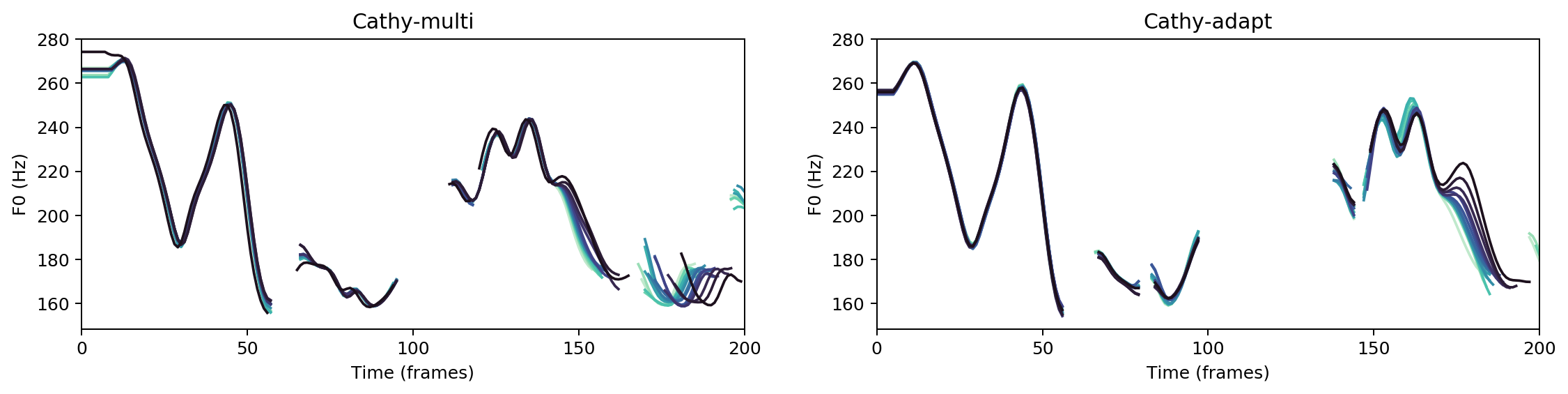
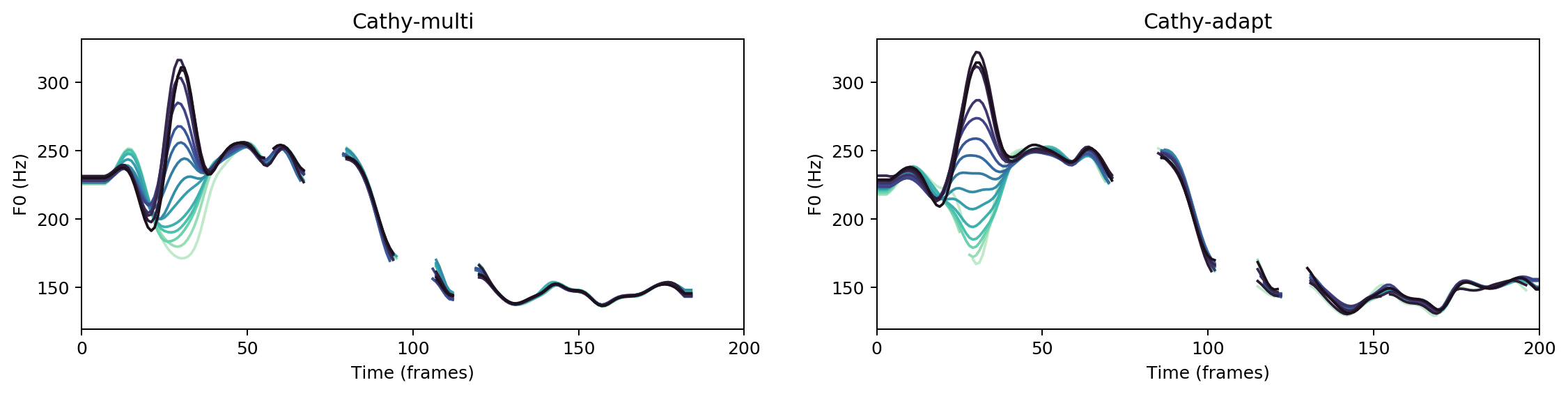
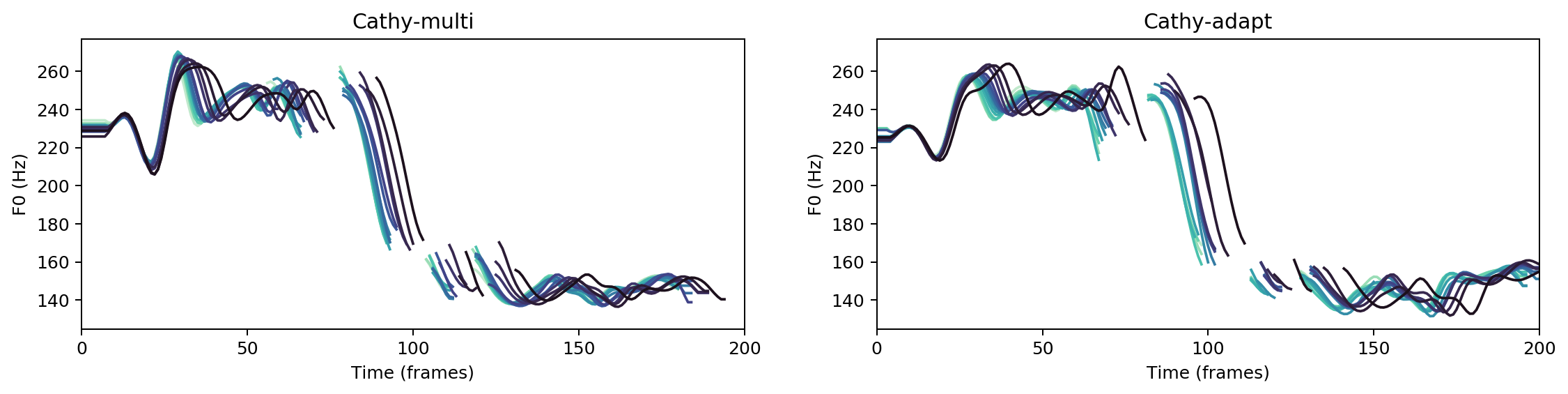
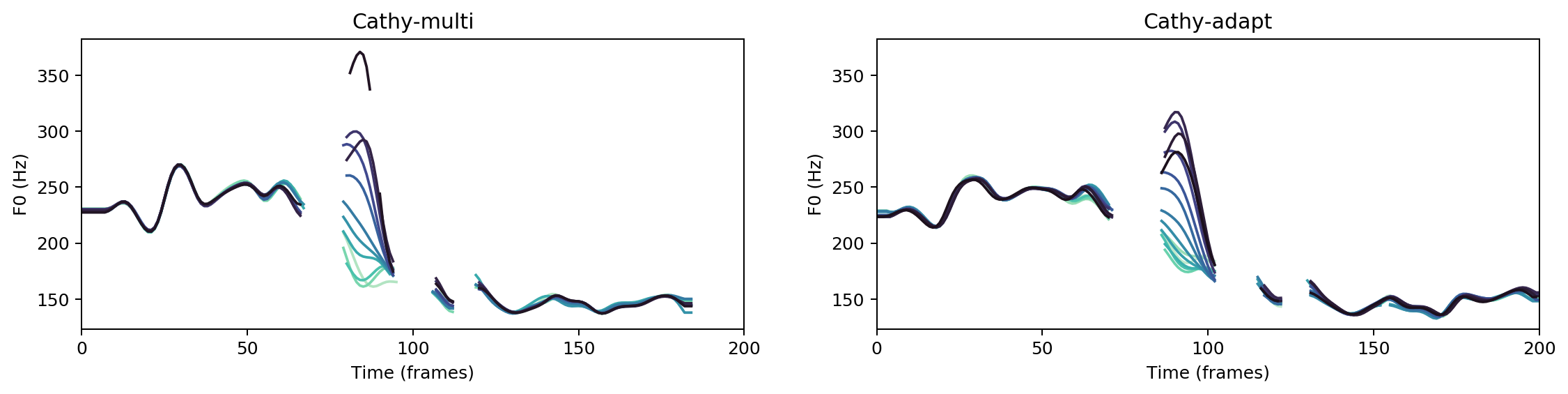
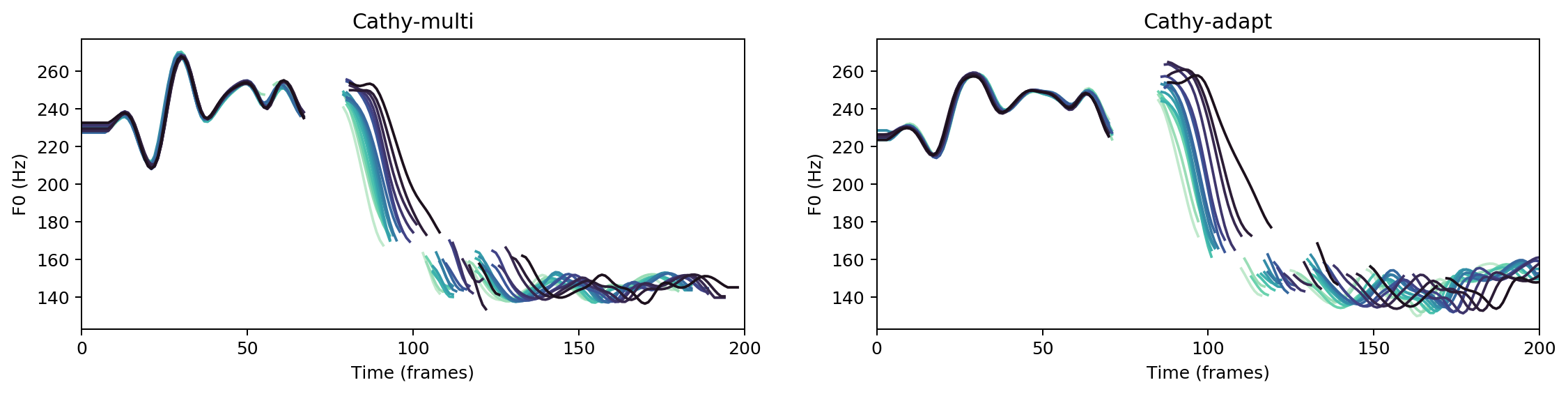
Multispeaker/speaker adaptation same voice comparison
“
He could see every object in his cottage. and his gold was not there.
Ground Truth
cathy-multi
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
cathy-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
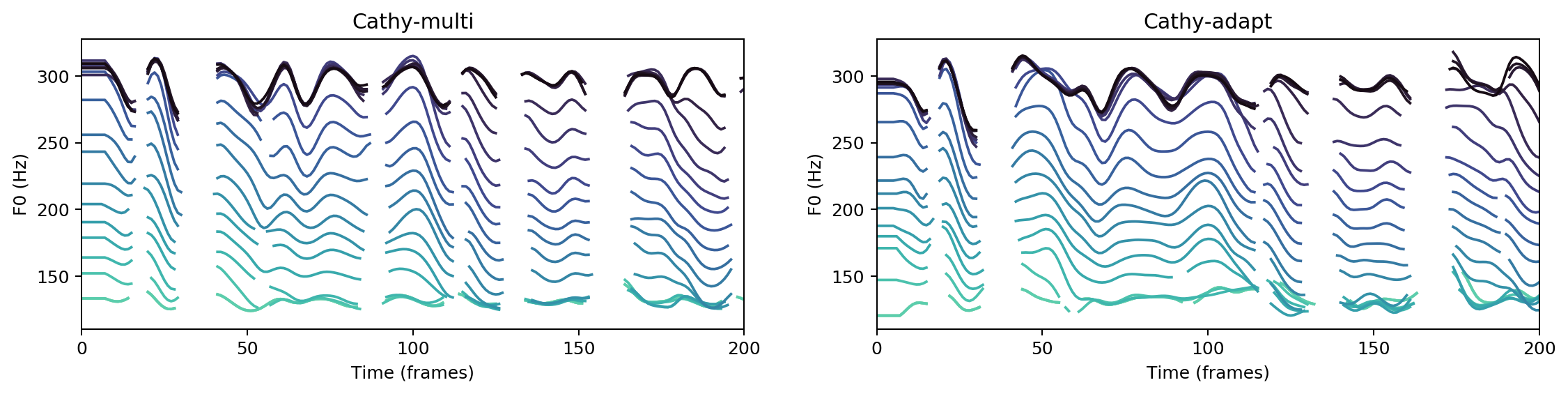
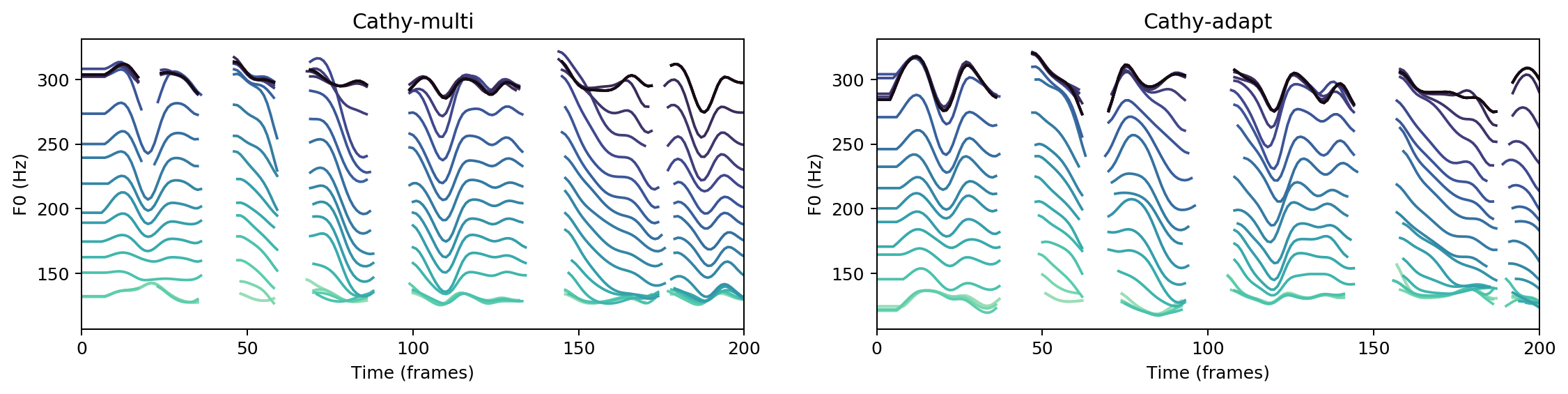
“
As they sat thus he heard a sound behind him and turned his head.
Ground Truth
cathy-multi
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
cathy-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
Speaker adaptation
“
His genius and ardour had seemed to foresee and to command his prosperous path.
Ground Truth
obama
jsj
lj
martha
obama-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
jsj-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
lj-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
martha-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
“
My brethren, these things ought not so to be.
obama-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
jsj-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
lj-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
martha-adapt
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11