Most of the prevalent approaches in speech prosody modeling rely on learning global style representations in a continuous latent space which encode and transfer the attributes of reference speech. However, recent work on neural codecs which are based on Residual Vector Quantization (RVQ) already shows great potential offering distinct advantages. We investigate the prosody modeling capabilities of the discrete space of such an RVQ-VAE model, modifying it to operate on the phoneme-level. We condition both the encoder and decoder of the model on linguistic representations and apply a global speaker embedding in order to factor out both phonetic and speaker information. We conduct an extensive set of investigations based on subjective experiments and objective measures to show that the phoneme-level discrete latent representations obtained this way achieves a high degree of disentanglement, capturing fine-grained prosodic information that is robust and transferable. The latent space turns out to have interpretable structure with its principal components corresponding to pitch and energy.
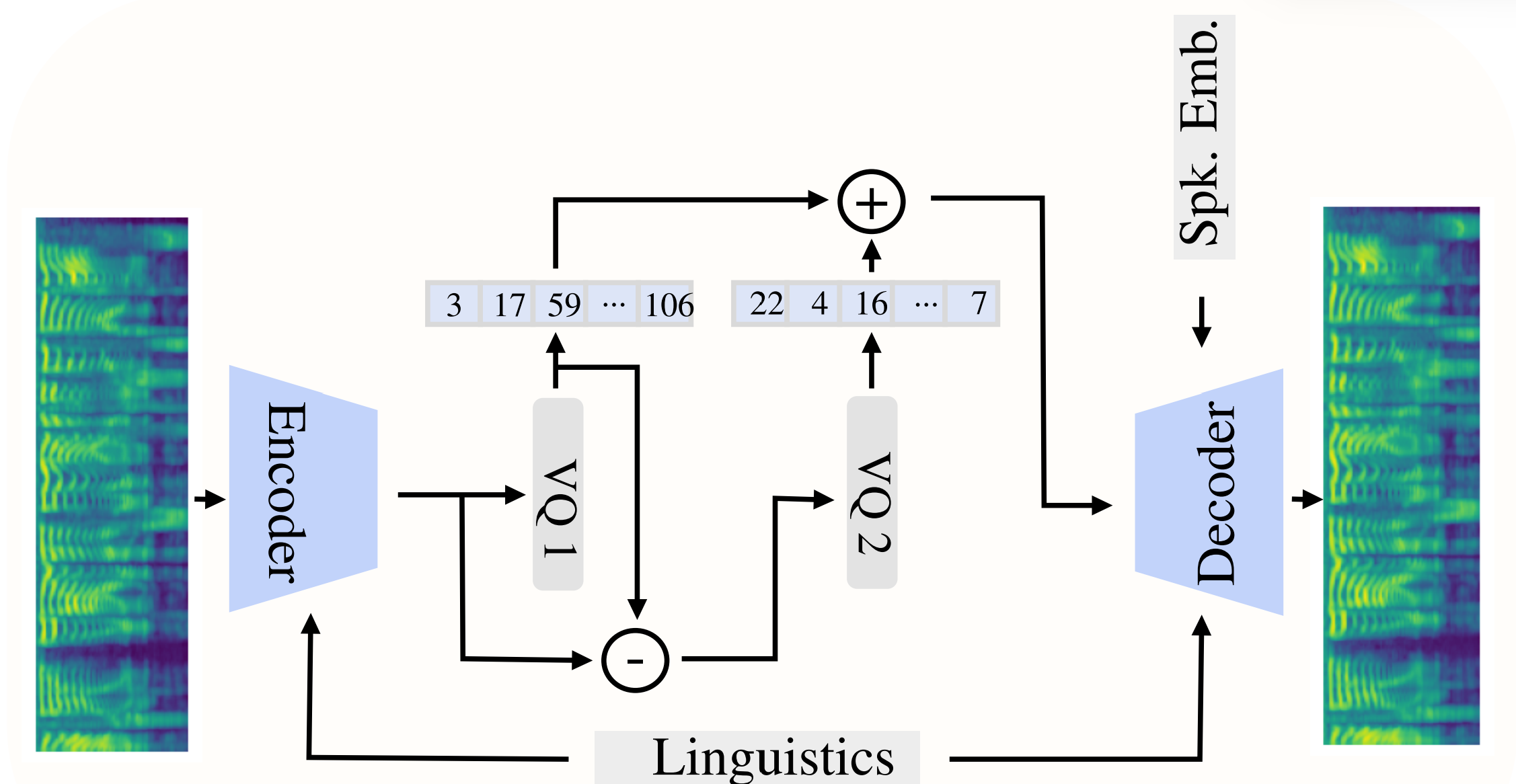
We perform Principal Components Analysis on the codes and examine the resulting components. The first two components are found to capture the vast majority of the variance of the data, namely 96%. To derive a qualitative interpretation of each of those two components, we select a set of codes from that space by varying each of the two dimensions separately. To do that, we draw a path along each dimension and select codes that lie approximately on this path at different positions, as shown by the red (PCA components 1) and green (PCA components 2) dots. We then use each selected code to synthesize all the phonemes of a reference utterance with two different speakers and analyze the generated audio for its mean pitch (F0) and mean energy (RMS). Interestingly enough, varying the first PCA dimension was highly correlated with the pitch of the generated sentence, while varying the second dimension was highly correlated with its energy.
|
|
In order to assert that the linguistic content is explained away from the latent representation, we resynthesize a set of evaluation utterances using their original linguistic content as conditioning, but for each utterance we shuffle its codes before feeding them to the decoder. If any linguistic information had leaked into the representation, then this shuffling of the latent codes would tamper the identity of generated phonemes and would result in reduced intelligibility.
In order to investigate the extent to which the speaker identity is explained away in the latent representation, we conduct a cross-resynthesis experiment where we encode audio from a source speaker and attempt to re-synthesize it using a speaker embedding of a different speaker. When the speaker embedding corresponds to the source speaker the task reduces to standard resynthesis. The main goal of this experiment is to empirically support that the latent space does not contain speaker identiy information by showcasing the ability of the model to combine freely code and speaker embeddings.
Notes:
- ▶ are the ground-truths, ▶ are the samples resynthesized with the same speaker, and ▶ are the cross-resynthesized samples.
- Clicking on the icon that appears next to some of the samples will pop up a figure with the pitch contours of the respective ground-truth, resynthesized and cross-resynthesized audio.
With this experiment, we investigate the ability of the prosodic representations to be transferred between two utterances. Given that the model operates on phoneme-level features, we select a set of utterances with a specific length in phonemes. We use one of them as the target utterance while the rest of them are used as source utterances. So the goal here is to transfer the prosody from all the source utterances into the target utterance by extracting the codes from each source utterance and combining them with the phoneme embeddings of the target utterance. We find that even with this simple method the F0 of the target speech is highly correlated with the F0 of the source speech, empirically supporting the transferability of the learned representations.